
Como selecionar o banco de dados ideal para o seu novo sistema
SQL or NoSQL that's the question


Atualmente existem diferentes tipos de bancos de dados no mercado e cada um deles se propõe a resolver um problema (ou um conjunto de problemas) específico. Nesse contexto, a melhor solução nem sempre está clara o suficiente para o problema a ser resolvido.
Além disso, em muitas situações, os profissionais da área de tecnologia da informação têm dificuldade em tomar decisões de forma pragmática e acabam usando vieses de maneira inconsciente sem perceber que a escolha da melhor tecnologia influencia no resultado final da solução e na produtividade do time.
Apesar de já ser um tema amplamente debatido por acadêmicos e profissionais de mercado e também explorado em diversas mídias, percebo que ainda carece discussões pragmáticas, principalmente em lingua portuguesa, que ajudem aos engenheiros na tomada de decisão.
A escolha do banco de dados adequado é crucial para atender às necessidades do negócio. Resolvi escrever o meu primeiro post sobre esse tema para ajudar aos engenheiros, independente do seu nível profissional, na (muitas vezes sofrida) escolha do banco de dados mais indicado para o problema que estão se propondo a resolver.
Bancos relacionais e NoSQL
Os SGBD's (Sistemas Gerenciadores de Bancos de Dados) em geral são classificados em duas categorias: Bancos relacionais e NoSQL.
Os Bancos de dados relacionais são baseados no modelo relacional, onde os dados são armazenados em tabelas com esquema/estrutura bem definida e são definidos relacionamentos entre essas tabelas.
Um exemplo simples: pense no conceito de Estado e Município. Ambos são bem diferentes entre si, mas sabemos intuitivamente que um Estado é composto de pelo menos um Município. Por isso dizemos que existe um relacionamento entre Estado e Município. Já os conceitos de Estado e Planeta não tem nada a ver um com outro. Logo não estão relacionados.
Já os bancos de dados NoSQL, representam um conjunto diverso de SGBD's não relacionais, ou seja, são uma forma diferente de organizar as informações onde não há necessariamente a preocupação com os relacionamentos entre os conceitos ou entidades. Aqui a preocupação maior é com questões como flexibilidade, escalabilidade e performance.
Bancos de dados relacionais
Bancos de dados SQL, também conhecidos como relacionais, armazenam dados em tabelas com linhas e colunas, e as relações entre tabelas são feitas por chaves primárias e estrangeiras. Eles seguem as propriedades ACID (Atomicidade, Consistência, Isolamento, Durabilidade) para garantir transações de dados confiáveis.
A seguir um exemplo de modelo relacional.
Os dados são armazenados em tabelas assim:
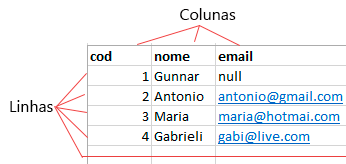
Os bancos relacionais mais utilizados atualmente são:
MySQL
PostgreSQL
Microsoft SQL Server
Oracle Database
SQLite
Bancos de Dados NoSQL
Bancos de dados NoSQL são sistemas não relacionais projetados para oferecer maior escalabilidade, flexibilidade e desempenho em cargas específicas de escrita e leitura. Eles não seguem o modelo relacional nem usam SQL como padrão, adotando diferentes modelos de dados e linguagens de consulta conforme o tipo de NoSQL.
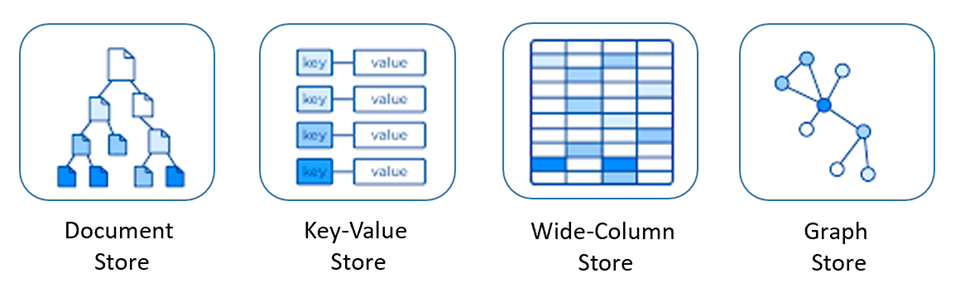
Diferentes tipos de bancos NoSQL
Documentos
Bancos de dados de documentos armazenam dados em documentos em formatos como JSON e XML, permitindo estruturas complexas e flexíveis. São usados para perfis de usuário, catálogos de produtos e gerenciamento de conteúdo, DevOps/Logging. Exemplos incluem MongoDB, ElasticSearch, Amazon DocumentDB e CouchDB.
Um documento NoSQL Json:

Chave-valor
Bancos de dados chave-valor armazenam dados como pares de chave e valor, sendo ideais para alto desempenho em leitura e escrita em modelos de dados simples. São usados em gerenciamento de sessões, caching, preferências de usuários e recomendações de produtos. Exemplos: Redis, Memcached, Amazon DynamoDB, Azure Cosmos DB e Riak.
Colunar (Wide-column databases)
Bancos de dados de colunar são baseados em tabelas, mas com flexibilidade nas colunas e dados. São usados em telemetria, dados analíticos, mensagens e séries temporais. Exemplos: Cassandra, HBase, Accumulo, Couchbase, ScyllaDB.
Grafos
Focados em representar dados e relações em forma de grafos, são ideais para aplicações que exigem consultas complexas de redes e conexões, como redes sociais, recomendações e análise de fraudes. Exemplos: Neo4j, ArangoDB, OrientDB, Amazon Neptune.
Séries temporais
Bancos de dados de séries temporais armazenam dados em fluxos ordenados por tempo, não por valor ou ID, utilizando carimbos de data/hora. São usados em telemetria industrial, DevOps e aplicações de IoT. Exemplos: Graphite, Prometheus, Amazon Timestream.
Orientados a Objetos (OODBMS)
Armazenam dados como objetos, de acordo com o paradigma de programação orientada a objetos. São usados para aplicações que requerem a modelagem de dados complexos. Exemplos: ObjectDB, db4o.
Decidindo entre Bancos Relacionais e NoSQL
Como engenheiro de software você vai precisar tomar a decisão de qual modelo de dados utilizar. Procurei resumir aqui as principais características de cada um para ajudar a dar mais clareza à sua escolha.
Estrutura e Modelagem de Dados
Bancos de dados SQL são ideais para dados estruturados com esquemas bem definidos, representados em tabelas. Eles exigem que qualquer alteração no esquema modifique toda a estrutura do banco. São adequados para aplicativos com modelos de dados previsíveis, como sistemas de gestão de inventário.
Bancos de dados NoSQL são projetados para dados não estruturados ou semi-estruturados e não exigem um esquema fixo, oferecendo maior flexibilidade para lidar com mudanças no modelo de dados. Eles são mais adequados para aplicações com modelos de dados em evolução ou conjuntos de dados variados, como redes sociais.
Consistência e Integridade
Bancos de dados SQL oferecem forte consistência e conformidade total com ACID, sendo ideais para aplicações que exigem consistência de dados e garantias transacionais, como sistemas bancários ou de comércio eletrônico.
Bancos de dados NoSQL geralmente sacrificam a consistência em favor da disponibilidade e tolerância a partições, seguindo o teorema CAP. Eles oferecem consistência eventual e conformidade parcial com ACID, sendo mais adequados para aplicações que priorizam disponibilidade e desempenho, como redes sociais, análise de dados ou motores de recomendação.
Escalabilidade e Desempenho
Bancos de dados SQL oferecem escalabilidade vertical, adicionando recursos a um único servidor para lidar com cargas aumentadas. Isso é adequado para aplicações de escalabilidade moderada, como aplicativos web pequenos a médios, mas pode ser caro e limitado devido à capacidade finita do servidor.
Bancos de dados NoSQL oferecem escalabilidade horizontal, permitindo distribuir dados por múltiplos servidores, facilitando o manejo de grandes volumes de dados ou altos volumes de tráfego. São ideais para aplicações em larga escala com grandes requisitos de dados e desempenho, como análise de big data, processamento de dados em tempo real ou aplicações IoT. Se sua aplicação precisa de escalabilidade fácil, os bancos NoSQL são a melhor escolha.
Complexidade de Consultas
Bancos de dados SQL oferecem capacidades avançadas de consulta com a linguagem SQL, permitindo operações complexas de filtragem, junção e agregação. São ideais para aplicações que exigem análises, relatórios ou data warehousing, onde consultas complexas são necessárias.
Bancos de dados NoSQL têm capacidades de consulta diversificadas dependendo do tipo de banco, mas geralmente não oferecem a mesma gama de funcionalidades que os bancos SQL. São mais adequados para consultas simples ou especializadas, como buscas por chave-valor, travessias de grafos ou pesquisas de documentos.
Performance e Latênica
Bancos de dados SQL oferecem um desempenho robusto e confiável para uma ampla gama de aplicações, mas não são otimizados para cargas específicas ou padrões de acesso.
Bancos de dados NoSQL são ideais para cenários que exigem alto desempenho e baixa latência, como altas cargas de escrita, armazenamento de grandes volumes de dados e relacionamentos complexos, oferecendo desempenho superior em determinados tipos de carga.
Como eu faço para escolher?
Os critérios que eu uso são bem simples: só escolho um banco NoSQL quando os requisitos do sistema que estou desenvolvendo são claros o suficiente para eu escolher um NoSQL. Caso contrário escolho bancos de dados relacionais.
Exemplo de requisitos e casos de uso que deixam claro o uso de um NoSQL:
Caching;
Análises de logs, dados de eventos ou telemetria;
Leitura ou escrita intensiva, isto é, maior que 10.000 requests por segundo:
Soluções que exigem baixa latência;
Latência: A exigência de que cada leitura seja completada em menos de 10 ms é uma forte indicação de tempo real.
Picos de carga: Se o sistema precisa lidar com picos repentinos de milhares ou milhões de leituras por segundo, isso indica leitura intensiva.
Alto volume de escrita: acima de terabytes (TB), alto velocidade de crescimento, leitura e escrita simultâneas;
Dados são complexos, não estruturados (como texto livre, imagens, logs, dados de sensores) ou mudam com frequência (e não se encaixam bem em um esquema fixo).
Redes sociais: Interações de bilhões de usuários, com posts, curtidas, comentários e dados de mídia.
Big Data: Dados de sensores em tempo real de sistemas IoT, como carros autônomos, dispositivos de rastreamento de saúde ou cidades inteligentes.
E-commerce e transações financeiras: Transações financeiras em tempo real ou dados de vendas, com milhões de registros processados diariamente.
Em resumo se o meu sistema vai lidar com algum desses desafios:
Grandes volumes de dados (> 1 TB);
Baixa latência (se a latência não for menor que 10ms vai dar ruim”);
Receber leitura ou escrita intensiva (10.000 requests por segundo);
Estrutura das informações é não é bem definida ou conhecida;
Requisitos fortes de alta disponibilidade;
Dados dados em tempo real;
Ao mesmo tempo que não necessita de transações ou de queries complexas;
Escolho NoSQL, caso contrário, vou de relacional sem medo de ser feliz. Isso significa que na maioria das vezes um banco de dados relacional vai atender bem as necessidades do meu sistema.
Aqui cabe ainda um breve comentário sobre estrutura de dados bem definida: os bancos relacionais há algum tempo permitem a criação de colunas com do tipo Json ou Array, isso significa que você pode obter um nível de flexibilidade mesmo em bancos de dados relacionais.
Próximos passos
Com esse artigo já é possível decidir qual banco de banco de dados usar grande maioria dos casos, entretanto, em alguns casos de uso, nos deparamos com a difícil escolha entre consistência e alta disponibilidade.
No meu próximo artigo pretendo explorar algumas estratégias de consistência bancos de dados distribuídos.